PIM Data Synchronization: Why is it so hard?#
This article was originally published by LWN.net. Here is a slightly updated version with information about the sync UI and a longer section on data modeling and handling. Recently, a SyncEvolution user described SyncML and some of its challenges in a LWN.net article. In this article, the author of that software adds more information for developers who want to synchronize data. Particular attention is given to Personal Information Management (PIM) data (such as contacts, events, tasks, notes) and how SyncEvolution and the underlying Synthesis SyncML Engine deal with the problems inherent in synchronizing that kind of data. It is worth pointing out that SyncML as protocol is data format agnostic and not limited to PIM. PIM is just the most common usage today - and particularly difficult.
Synthesis just made their core technology available under the LGPL v2.1 and 3.0. SyncEvolution 0.9 beta 1 is the first open source program using this libsynthesis. Together, these two projects are the [core building blocks for data synchronization][6] in the Moblin project.
PIM Synchronization: Challenges#
Whenever your author hears the song 1974 song “Rikki don’t lose that number”, he wonders whether the advice to “send it off in a letter to yourself” is still valid today, or whether we can trust our software to keep important phone numbers safe and sound. Why is synchronization software for PIM data still not 100% reliable?
Database replication is a well understood problem. But PIM data is special in many ways. First, there is no globally unique identifier (GUID) for items. When comparing two databases for the first time, there is often no additional meta information, beyond the data itself. Without a GUID in the item data, it is hard to determine whether two items from different databases refer to the same entity. In particular, because the content and/or representation of the same logical entity is often different in different databases (second problem).
For PIM data, the storage and exchange formats are typically vCard 2.1/3.0, vCalendar 1.0 and iCalendar 2.0. At first glance it seems that items in these formats have a GUID. But the UID property in a vCard is not mandatory, neither in version 2.1 nor 3.0 of the standard. Even if it is used by a particular software, it is not guaranteed to be globally unique and therefore cannot be relied upon when comparing two different databases. Same problem exists with vCalendar 1.0, which is still the most common format used by consumer devices for events and tasks. Only iCalendar 2.0 specifies a mandatory, global UID property because it is required for exchanging meeting invitations.
Without a GUID, one has to compare the content of items to identify matching items. But the PIM data formats allow many different, often more or less complete implementations and representations of the same information. One side of an implementation might support just the bare minimum of information for a contact (for example, name and phone number), while the other side may support everything defined in the standard (photo, arbitrary number of email addresses, and phone numbers), plus non-standard extensions (spouse, instant messaging handles). A simple byte comparison, without any understanding of the semantic of the data, is, therefore, not good enough.
After identifying matching items, there is a third problem: if the items differ in some properties, which item is more up-to-date? There are REV and LAST-MODIFIED properties, but again support for them is not guaranteed. Worse, both items might been created or updated independently, so that each has valid information the other does not have (new phone number added on my cell phone, address changed on my desktop, based on an email with that information).
Fourth, it is necessary to support these data formats to be interoperable with existing devices. One cannot simply choose a custom data format that avoids the previous three issues. Neither is it possible to make assumptions about the implementation of a peer and what it may or may not support.
Fifth, not knowing enough about a peer is particularly problematic when receiving an item back from a peer. If a property is missing, that was sent to the peer earlier, does that mean that the user has removed this piece of information or that the peer was unable to store it? In the former case, the property must also be removed locally. In the latter, it needs to be preserved while updating the other properties. Only allowing one-way synchronization avoids this problem, but is also considerably less useful.
SyncML#
The SyncML protocol (aka Open Mobile Alliance Data Synchronization, OMA-DS) itself is fairly simple, at least up to and including version 1.2.1, the latest version supported by Synthesis and most other implementations. SyncML defines a general message format with encodings, both as XML and as more compact WAP Binary XML (WBXML). Exchanging these messages over HTTP (as POST and reply) and Bluetooth is also standardized. A typical session requires three message exchanges. When sending many small data items (~2KB) with WBXML as encoding, the measured data overhead for the SyncML protocol was 8%, 2.5 times less than XML.
During a sync session, a client talks to a server. The protocol is intentionally not symmetric. A client is fairly simple to implement and usually only talks to one server. The server implements all of the advanced logic, like tracking the state of multiple clients, matching items, and merging data.
A client has to keep track of local changes (added/removed/updated) between sync sessions, using its own locally unique identifier (LUID) to refer to items. It has to be able to export, import, update, and delete items. The server has to maintain a mapping between GUIDs and the corresponding LUIDs that are used by each client.
At the start of a sync session, client and server authenticate each other and negotiate which databases they want to synchronize (identified by a Uniform Resource Identifier (URI)) and which data formats are acceptable (MIME types). In theory, this information could be used to configure clients automatically. In practice, it is often necessary to configure manually because the information is only sent for URIs that are listed explicitly, leading to a chicken-and-egg problem.
The information about supported data types can be detailed enough to describe which properties of the different PIM formats are supported by a client or server. The Synthesis engine generates this information for its peer automatically from the configuration (more on that below) and uses the information received from its peer to merge updates intelligently. Other servers check this information only to determine whether specific properties, like PHOTO, are supported and then they hard-code the rest of the data handling.
As part of getting client and server ready for a synchronization, both agree on the sync modes for active databases. The standard specifies one-way and two-way synchronization, both incrementally (the only changes sent are those made since the last synchronization) and complete (all currently existing items have to be sent). For the initial session or after a failure, this “slow” mode is used to get client and server in sync (again), that is ,the client sends all of its items, then the server compares those items against its own data and sends back changes to the client. As explained above, this matching is problematic, therefore the standard also supports complete sync modes, where one side is told to wipe out all data before receiving items (“refresh from client” and “refresh from server”).
A session concludes when both sides have sent their changes and some meta information (for example, new LUIDs assigned by the client). The standard defines a mechanism for suspending a session earlier than that and resuming it later. The same resume mechanism can also be used to recover from an unexpected loss of connection. This is an optional feature of the standard, supported by the Synthesis implementation but not all servers. Without this feature, a slow sync is necessary to keep client and server reliably in sync.
Synthesis SyncML Engine + SyncEvolution#
Both the Synthesis SyncML Engine and SyncEvolution are implemented in C++. Synthesis paid particular attention to portability of their code to platforms with less capable compilers. Therefore, the choice of C++ features used is intentionally limited (no hard dependency on exception support, moderate use of templates, and the standard template library). SyncEvolution is less restricted and uses both exceptions for error reporting and the “resource acquisition is initialization” (RAII) design pattern to track resources, plus Boost templates (but no Boost libraries at this point).
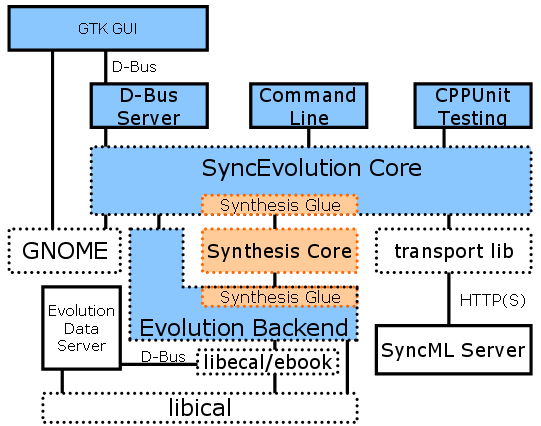
The diagram shows how the two projects interact and fit into the Moblin infrastructure. Solid boxes represent executables and dotted boxes represent libraries. The GUI communicates with the core engine via D-Bus. Long term this will allow the engine to run completely independently from a particular front-end. The command line tool currently still calls libsyncevolution directly and thus does not depend on D-Bus. When D-Bus is available, it should instead act like another front-end for the D-Bus server. The engine itself is compiled into a library with two stable, plain C APIs:
an API for a SyncML client user interface, like SyncEvolution
a database API for plug-ins, which connect the engine with local data
The BSD-licensed SDK provides a glue mechanism that can be linked statically to access these APIs in C++, without tying clients closely to the implementation. Bindings for Java are available from Synthesis under a commercial license. The official documentation for this is the Synthesis “SDK and Plug-in Interface” reference manual, which is included in the open source distribution.
The same API is also designed for using the engine in a SyncML server, but this part of the API is not completely implemented at this time. The code for the server role exists and is used in Synthesis’ server products. It is mostly identical with the code that is used by clients.
The engine uses the same XML-based configuration mechanism in both roles. Data format support is not hard-coded in the engine. Instead, the XML configuration defines datatypes and their mapping to the standard formats. So, when using Synthesis for both client and server, the definition of a custom data format has to be written only once. The engine can automatically store data defined this way in a relational database using the Open Database Connectivity (ODBC) API, so it might not even be necessary to write C or C++ code.
Because of the shared engine, clients automatically have some of the features normally found only in SyncML servers, like interpreting device information and intelligently updating only those properties of an item really supported by a peer. With well written peers, this goes a long way towards solving problems four (making assumptions about the peer) and five (getting incomplete items back). For cases where the information provided by a peer is insufficient, the engine also has possibilities for making item parsing and generation depend, for example, on the peer name and/or firmware version.
The engine itself does not implement a particular message transport, which minimizes system dependencies and allows adding custom transports without changing the engine. The client calling the engine is responsible for receiving messages, which are then processed by the engine, and for sending messages generated by the engine. SyncEvolution provides that part for HTTP(S), using either libsoup or libcurl, depending on how it was configured during compilation. It also provides a command line tool, which configures a client and runs a sync session, something which is currently missing in the Synthesis open source release itself. The SyncEvolution 0.9 beta 1 source tar ball includes a copy of the engine source and compiles everything with one “configure; make; make install” invocation. This is the most convenient way of getting started using the source code.
Originally, SyncEvolution was a tool for the Evolution mail and PIM application, but it was always meant to be more flexible and can be compiled without depending on Evolution or GNOME. The Evolution backend is just one of many. Plain files (used for KDE synchronization) and Mac OS X Address Book are also supported. More backends could be added as described in a blog article. The file backend synchronizes files inside a directory and is portable, so it can always be compiled. When adding these backends, your author dodged the bullet of having to rename the project by reinterpreting the name as “SyncEvolution - the missing link”…
Another important component of SyncEvolution is a CPPUnit-based [testing system][23], which runs local database access tests, as well as integration tests with real SyncML servers. With the help of the “synccompare” comparison tool, it checks for data modifications when importing and exporting items locally and sending items back and forth.
Data Modeling and Handling#
After introducing Synthesis and SyncEvolution, there is still the question: how are the tricky PIM data handling issues solved?
At the core of each kind of data (contacts, calendar items, notes) is a Synthesis “field list”. This list has to define the information that the engine is expected to handle for each item completely.; Iinformation which is not declared will be ignored, and may be removed when modifying data locally. The format of a field list is a more or less flat key/value mapping with unique keys, which is easier to process than complex structured information, like a vCard. Items are exchanged between the engine and DB plug-ins as one field list per item. This allows interfacing with local data storage without having to deal with the more complex formats. In cases where the local storage is based on these formats, it is also possible to ask the engine to exchange the data as a string. This is how SyncEvolution backends operate. They cannot access the field list given the current SyncEvolution API, but this could be added.
Each key refers to a value of a certain built-in type, or arrays of such values for properties which can occur multiple times. Arrays of complex types and multi-dimensional arrays are avoided.
A complete description of the format is available in the “XML Configuration Reference for Synthesis SyncML Server&Client Products”. Here is a simplified example from the “syncclient_sample_config.xml”:
<fieldlist name="contacts">
<field name="N_LAST" type="string" compare="always"/>
<field name="N_FIRST" type="string" compare="always"/>
<field name="N_MIDDLE" type="string" compare="always"/>
<field name="N_PREFIX" type="string" compare="conflict"/>
<field name="TEL" array="yes" type="telephone" compare="conflict"/>
</fieldlist>
The names can be chosen arbitrarily. The “compare” attribute determines how the engine uses the field when comparing items. I: in this example, the full name is used as the primary key to find matches during a slow sync (problem one). The other properties are only used only when resolving conflicting changes during an incremental sync. Individual fields can be configured in a similar way to handle merging.
There are many different supported types. The “telephone” type, in this example, is different from “string” because the comparison is relaxed and only uses relevant digits (ignores separators like spaces, dashes, or slashes).
The conversion to and from external, standardized formats is again entirely driven by the XML configuration. A “mimeprofile” defines how these fields map to properties in a vCard. Both the standardized MIME profile and the slightly different legacy vCard 2.1 and vCalendar 1.0 formats are supported. In addition, plain text and RFC 822 mail formats are supported. Other formats like XML are possible, but have not been implemented.
Simple properties have a 1:1 mapping to fields. More complex properties, like the one which lists name components in a vCard, map to multiple fields. Repeating properties like phone numbers map to arrays. The same profile can be used for legacy and standard formats and for different peers, by enabling or disabling properties depending on the context in which the profile is used. Therefore there are two ways to define different external representations: it is possible to disable parts of a profile conditionally as define multiple profiles which use the same field list. Then data conversion is done by parsing with one profile and encoding with another.
The semantic associated with a profile definition is sufficient to generate the SyncML Device Information from that profile automatically. When receiving data, the engine uses the peer’s Device Information to determine which properties in the profile are supported by the peer and only modifies those locally. This way, fields which are not supported by a profile (no mapping) or not supported by a peer (mapping not enabled) are preserved when receiving an update (problem five).
There are cases that even the rather flexible profiles cannot handle. For these cases, the engine invokes scripts defined in the XML configuration for specific situations, like post-processing an item just received from a peer. Such a script has access to global variables of the session, as well as the field list. For example, this script sanitizes summary and description of an event by stripping trailing and leading spaces with the help of a built-in function:
<macro name="VCALENDAR_INCOMING_SCRIPT">
DESCRIPTION=NORMALIZED(DESCRIPTION);
SUMMARY=NORMALIZED(SUMMARY);
</macro>
Open Issues + Ideas#
High on the list of items to work on next is to integrate a SyncML server into the Linux desktop. Synthesis offers a “traditional” http server for Linux and Windows, but this is designed for interaction with remote devices over the Internet. For a local desktop, Bluetooth is perhaps more important. Such a desktop server could also offer a GUI that the user can use to control it and interactively influence its operation. During merge operations, current Internet-based SyncML servers are limited to executing hard coded heuristics and have the difficult choice between duplicating or dropping information. A local server could ask the user to help with merging conflicting items.
The data conversion routines in the Synthesis Engine are currently tied to a SyncML session context. After some non-trivial, but doable, code refactoring, these routines could also be exposed as a set of simple API calls. This may be useful in various projects, like OpenSync.
The goal is to continue with SyncEvolution and Synthesis, not just as open source, but also as open projects, with as much communication on public channels as possible. We are actively seeking involvement and feedback as we get these projects going.